TL;DR. Large language models (LLMs) write code fast, and sometimes that code removes your auth middleware, pastes API keys into CI, or downgrades HTTPS without warning. The fix is defense in depth: pre-commit hooks block obvious problems, automated review agents catch logic errors and context-blind mistakes, and continuous integration (CI) blocks merges when anything slips through. The full stack adds ~30 seconds per commit and ~$20/month in API spend.
Introduction#
Large language models (LLMs) have become capable coders. But they can do unintuitive things in the name of finishing a task. They will happily remove your authentication middleware if it speeds them up. They'll downgrade HTTPS to HTTP if it simplifies the config. They'll paste your API keys directly into GitHub Actions if you don't stop them.
These aren't hypotheticals. In the past month, I've caught Claude attempting to:
- Store Open Authorization (OAuth) tokens in plaintext JSON files
- Remove cross-site request forgery (CSRF) protection because "it was causing test failures"
- Use
eval()to parse user-provided configuration - Commit a
.envfile with production database credentials - Update test PostgreSQL credentials—which already had
# pragma: allowlist secretappended, bypassing the secrets pre-commit hook—with my actual production admin credentials to get a test working - Truncate a 400-line Svelte component down to 50 lines on a targeted edit, losing authentication logic in the process
LLMs are powerful coding assistants, but they lack the paranoia that keeps production systems secure. They optimize for task completion, not operational safety. The fix (thankfully) isn't to stop using them. It's to build safety nets that catch dangerous code before it ships.
This post covers the defensive layers I use across my projects. Pre-commit hooks block insecure patterns. Automated review agents catch context-blind mistakes. Continuous integration (CI) workflows fail loudly when LLMs generate problematic code. These patterns come from my TaskManager and agents repos, where LLM-generated code meets production security requirements. The same patterns also apply to securing Model Context Protocol (MCP) servers and OAuth implementations, a topic I'll cover in more depth at CactusCon.
The Multi-Layer Defense Strategy#
Traditional security assumes humans write code and occasionally make mistakes. LLM-assisted development inverts this: the baseline is fast, confident, and potentially catastrophic. Security becomes about layers that verify rather than trust.
The model is simple:
| Layer | What it catches | When it runs | Can be bypassed? |
|---|---|---|---|
| Pre-commit hooks | Patterns, secrets, type errors | Before commit | Yes (--no-verify) |
| Review agents | Logic errors, context mismatches | On PR creation | Yes (ignore comments) |
| CI workflows | Everything above + integration | Before merge | No (if set up to block merge) |
Each layer catches different failure modes. Together, they create defense in depth.
Layer 1: Pre-commit Hooks (The First Line)#
Pre-commit hooks run on your local machine before code even reaches git. This is your first chance to catch LLM hallucinations, insecure patterns, and configuration mistakes.
Here's a sample of the pattern I use across Python projects (from taskmanager/.pre-commit-config.yaml):
repos:
# Secret detection - catches leaked credentials
- repo: https://github.com/Yelp/detect-secrets
rev: v1.5.0
hooks:
- id: detect-secrets
args: ['--baseline', '.secrets.baseline']
# Python linting and formatting (ruff replaces black, isort, flake8)
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.8.6
hooks:
- id: ruff
args: [--fix, --exit-non-zero-on-fix]
- id: ruff-format
# Type checking - verifies type hints
- repo: local
hooks:
- id: pyright
name: pyright
entry: uv run pyright
language: system
types: [python]
pass_filenames: false
# Security scanning
- repo: https://github.com/PyCQA/bandit
rev: 1.9.2
hooks:
- id: bandit
args: ['-c', 'pyproject.toml']
What this catches:
- Secret leaks: LLMs sometimes paste API keys directly into code.
detect-secretsblocks commits that contain credential patterns. - Type inconsistencies: LLMs can be sloppy with types.
pyrightenforces strict typing. - Security anti-patterns:
banditflags insecure crypto, SQL injection risks, and hardcoded passwords.
Running Tests in Pre-commit
The agents repo runs tests in pre-commit (agents/.pre-commit-config.yaml):
- repo: local
hooks:
- id: pytest
name: pytest
entry: uv run pytest
language: system
types: [python]
pass_filenames: false
stages: [pre-commit]
This is aggressive but effective. If an LLM change breaks tests, you know immediately, before the commit happens.
Trade-off: For large test suites, this can be slow. My approach:
- Pre-commit: Fast unit tests only (< 30 seconds)
- CI: Full test suite including integration tests
Layer 2: Code Review Agents (Context Checking)#
Pre-commit hooks are great at catching bad patterns. Review agents go further: they analyze the whole system and catch logical inconsistencies. LLMs are excellent at spotting code smells, inconsistent patterns, and architectural violations. But that only works if you give them the right prompt and the right scope.
Local Agents
My most valuable agent checks run locally, where they have access to extensive tooling for reviewing the codebase. I keep four main agents in my claude-code-agents repo. I fire them off in parallel to review code optimization, test coverage, dependency management, and security concerns.
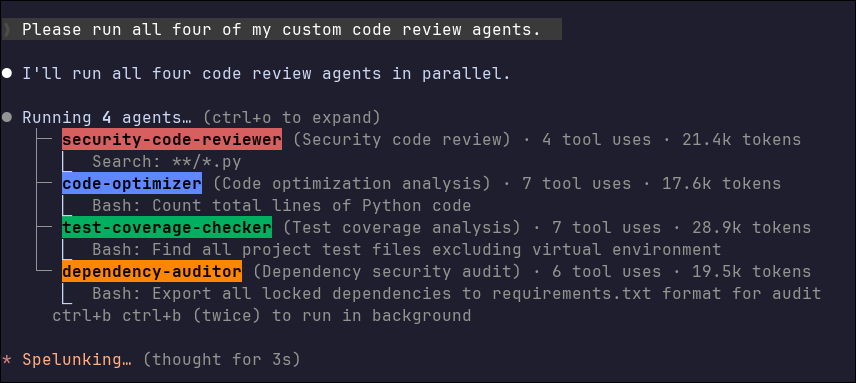
Each agent is tuned to one goal so its context window stays clean. The agents don't make changes directly. The main Claude Code instance summarizes their findings and prioritizes what to fix. Here's what they found when I ran them against my agents repo:
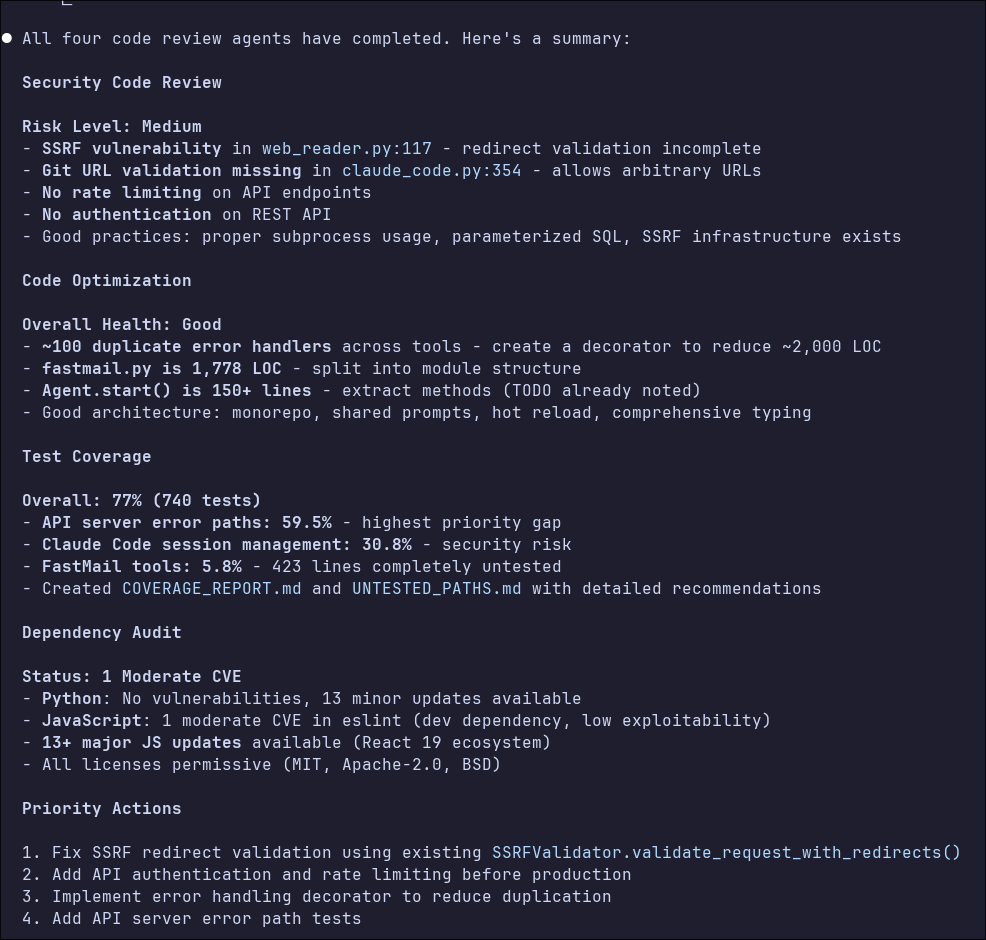
These checks can be token-intensive. The run in the screenshot above used over 250k tokens. It's worth being intentional about which agents to run and when, especially if you're watching costs. I typically don't run these for every PR. More like once a week, or when the codebase feels like it's getting messy.
Why this works:
- Read-only analysis: The agents use many tools (~250 combined in the example above), but they don't make any changes. They provide recommendations. You can have Claude fix them later, or address them yourself.
- Repository context: The
CLAUDE.mdfile provides architecture patterns, security requirements, and coding standards. - Specialization: LLM performance declines as context gets polluted with unrelated concerns. Having each agent specialize in one aspect lets it do more thorough work.
- Human-in-the-loop: The agents report findings. A human decides what to act on.
Agents in CI
Here's how I use Claude Code in GitHub Actions to review every PR (taskmanager/.github/workflows/claude-reviews.yml).
One especially valuable catch: the CI review agent regularly finds cases where my local Claude Code session emptied or truncated files, losing significant amounts of code. This happens more often than you'd expect. The main causes are full file rewrites (Claude regenerates an entire file from memory instead of making a targeted edit), output token limits (hitting the max mid-stream leaves you with a truncated file), and context pollution (longer sessions make it harder to reproduce file contents accurately).
Large files, many files modified in the same session, and complex multi-step changes all make truncation more likely. The mitigation is straightforward: commit often, keep files modular, and start fresh sessions for risky operations. Having a CI agent with clean context sanity-check every PR has caught many truncation issues that would otherwise have reached main and caused runtime failures.
name: Claude Code Review
on:
pull_request:
types: [opened]
jobs:
claude-review:
runs-on: ubuntu-latest
permissions:
contents: read
pull-requests: read
issues: read
id-token: write
steps:
- name: Checkout repository
uses: actions/checkout@v6
with:
fetch-depth: 1
- name: Run Claude Code Review
uses: anthropics/claude-code-action@v1
with:
claude_code_oauth_token: ${{ secrets.CLAUDE_CODE_OAUTH_TOKEN }}
prompt: |
REPO: ${{ github.repository }}
PR NUMBER: ${{ github.event.pull_request.number }}
Please review this pull request and provide feedback on:
- Code quality and best practices
- Potential bugs or issues
- Performance considerations
- Security concerns
- Test coverage
Use the repository's CLAUDE.md for guidance on style and conventions.
Use `gh pr comment` with your Bash tool to leave your review as a comment on the PR.
Why this works:
- Limited tool access: The agent can only use
ghcommands (view PRs, leave comments). It can't push code or modify workflows. - Repository context: The
CLAUDE.mdfile provides architecture patterns, security requirements, and coding standards. - Human-in-the-loop: The agent comments on PRs but doesn't auto-merge. A human makes the final call.
Security-Focused Review Agent
I run a second review agent specifically for security (taskmanager/.github/workflows/claude-reviews.yml):
prompt: |
Please perform a security-focused review of this pull request. Analyze the changes for:
**Security Concerns:**
- Authentication and authorization vulnerabilities
- Injection attacks (SQL, command, code injection)
- Sensitive data exposure (credentials, API keys, PII)
- Insecure dependencies or imports
- Path traversal or file access issues
- Improper input validation or sanitization
- Cryptographic weaknesses
- OAuth/token handling issues
- Race conditions or TOCTOU vulnerabilities
**Code Quality (security-relevant):**
- Error handling that might leak sensitive info
- Logging that might expose secrets
- Unsafe deserialization
- Resource exhaustion possibilities
What the Security Agent Actually Catches
Here are three real examples from my repos where the security agent caught issues that static analysis would miss.
1. Open Redirect Bypass (PR #160)
The agent flagged that my redirect validation using startswith() was bypassable:
if parsed.scheme and not return_to.startswith(settings.frontend_url):
raise errors.validation("Invalid redirect URL")
Issues identified:
- Protocol-relative URLs like
//evil.com/phishinghave no scheme but redirect externally- Subdomain attacks:
http://localhost:3000.evil.com/passes thestartswith()check- User-info attacks:
http://localhost:[email protected]/bypasses naive checks
Static analysis tools verify that redirect validation exists. They can't reason about whether the logic is correct.
2. Race Condition in Registration Codes (PR #141)
The agent identified a time-of-check-to-time-of-use (TOCTOU) vulnerability in single-use registration codes:
await validate_registration_code(db, request.registration_code) # Check
# ... user creation happens here ...
await use_registration_code(db, request.registration_code) # Increment (too late!)
Attack scenario: Admin creates a code with
max_uses=1. Attacker sends 10 concurrent requests. All 10 pass validation before any increment the counter. Result: 10 users created instead of 1.
Static analysis cannot detect race conditions. That requires reasoning about concurrent execution.
3. Incomplete Authorization Check (PR #152)
The agent caught a subtle issue adjacent to insecure direct object reference (IDOR):
When updating a todo with a
project_id, the code silently setsproject_nameandproject_colortoNoneif the project doesn't belong to the user — but doesn't reject the request. A user could associate a todo with an unauthorized project ID.
Static analysis sees that an authorization check exists. It can't determine that the check is incomplete.
The pattern across these examples: the security agent catches logic flaws (wrong validation, race conditions, incomplete authorization) rather than syntactic issues (missing sanitization calls, dangerous functions). That's the key differentiator from static analysis.
The security agent also catches context-dependent issues, like inconsistent protection across endpoints. An LLM might add authentication to /api/login but forget to protect /api/users. The review agent spots the missing auth on sibling endpoints because it understands the intent of the code, not just its patterns.
Cost consideration: Each review costs ~$0.10-0.50 depending on PR size. For active repos, this adds up. Consider:
- Running reviews only for PRs from external contributors
- Using Haiku instead of Sonnet for routine reviews
- Filtering by file patterns (e.g., only review changes to
auth/orapi/)
Layer 3: Comprehensive CI Workflows (The Safety Net)#
Pre-commit hooks run locally (they can be skipped with --no-verify). Review agents comment on PRs (humans can ignore them). CI is the enforced safety net that blocks merges.
I use reusable workflows from my workflows repo that provide consistent security checks across projects.
Python CI with Security Layers
The python-ci.yml workflow (workflows/.github/workflows/python-ci.yml) runs:
- Linting (ruff)
- Type checking (pyright or mypy)
- Tests with coverage (pytest + codecov)
- Package build verification (twine check)
- Security scanning (bandit)
Usage in a project:
# .github/workflows/ci.yml
name: CI
on:
push:
branches: [main]
pull_request:
jobs:
ci:
uses: brooksmcmillin/workflows/.github/workflows/python-ci.yml@main
with:
package-name: taskmanager
run-type-check: true
run-lint: true
run-tests: true
run-security: true
secrets:
CODECOV_TOKEN: ${{ secrets.CODECOV_TOKEN }}
This enforces that every PR must pass linting, type checking, tests, and security scans before merging. If an LLM change breaks any of these, the PR is blocked.
Tip: Use public repos for testing CI pipelines. They get unlimited GitHub Actions minutes. I've hit my monthly minutes limit on private repos when experimenting with pipeline configurations.
Multi-Tool Security Scanning
For production systems, I run layered security scans (workflows/.github/workflows/python-security.yml):
jobs:
security-scan:
steps:
- name: Run Bandit (Python SAST)
- name: Run Safety (dependency vulnerabilities)
- name: Run pip-audit (Python-specific CVEs)
semgrep:
# Advanced SAST with semantic patterns
run: semgrep scan --config=p/security-audit --config=p/secrets --config=p/python
codeql:
# GitHub's semantic code analysis
uses: github/codeql-action/init@v3
trivy:
# Filesystem and dependency scanner
uses: aquasecurity/trivy-action@master
Why multiple tools? Each one is good at a different thing: static application security testing (SAST), dependency CVE scans, taint analysis, and container/filesystem checks.
| Tool | What it catches | Example |
|---|---|---|
| Bandit | Python-specific anti-patterns | eval(), weak crypto |
| Safety/pip-audit | Known CVEs in dependencies | Vulnerable Flask versions |
| Semgrep | Semantic patterns | SQL injection via f-strings |
| CodeQL | Advanced taint analysis | User input flowing to os.system() |
| Trivy | Container/filesystem vulns | Secrets in Docker layers |
LLMs might suggest an old library version, use a deprecated crypto function, or construct SQL queries unsafely. One of these tools will catch it.
The same pattern applies to other languages. Rust projects use cargo-audit and cargo-deny. Go uses govulncheck. The principle is the same: multiple specialized tools for comprehensive coverage.
Context Management: The CLAUDE.md Pattern#
LLMs need context to make good decisions. The CLAUDE.md file provides this context in the repository itself, so review agents, coding assistants, and automated tools all understand:
- Architecture patterns: "Use async SQLAlchemy for database queries"
- Security requirements: "Always use prepared statements, never f-strings for SQL"
- Dependency conventions: "Use
uvfor package management, not pip" - Code style: "Type hints required, use
str | NonenotOptional[str]"
Example from taskmanager/CLAUDE.md:
### Response Formats
**Success responses:**
```json
// List/Collection: { "data": [...], "meta": { "count": 10 } }
// Single resource: { "data": { "id": 1, "title": "...", ... } }
```
**Error responses:**
```json
{
"detail": {
"code": "AUTH_001",
"message": "Invalid credentials",
"details": { ... }
}
}
```
When Claude generates API endpoints, it follows this exact format because it's documented in CLAUDE.md. Without this context, every endpoint would have an inconsistent response structure.
What to Include in CLAUDE.md
From my experience, these sections prevent the most LLM mistakes:
- Quick commands: "How do I run tests?" → Stops the LLM from inventing commands
- Architecture overview: "What patterns does this codebase use?" → Enforces consistency
- Security requirements: "What should never be committed?" → Blocks credential leaks
- Common tasks: "How do I add a new API endpoint?" → Provides working examples
- Anti-patterns: "What should I never do?" → Explicit guardrails
The Cost/Benefit Reality#
These layers add friction. Here's what it actually costs:
Time costs:
- Pre-commit hooks: ~30 seconds per commit
- CI pipeline: ~3-5 minutes per PR
- Review agent comments: ~2 minutes to read and address
Dollar costs:
- GitHub Actions: Free tier covers most personal projects
- Local agents: Can use a Claude subscription OAuth key. In my experience, running all 4 custom agents at once costs $4-5.
- Claude API for reviews: Can use a Claude subscription OAuth key, or via API ~$10-30/month for active repos (depends on PR volume)
- Security scanning tools: All free/open-source
What you avoid:
- A single credential leak can cost thousands in incident response
- A production auth bypass is a career-defining mistake
- Manual code review of LLM output takes 10x longer than automated checks
The math is simple. 30 seconds per commit is cheap insurance against shipping LLM-generated vulnerabilities.
What's Next: MCP Security#
These patterns apply directly to securing MCP servers. When you build tools that LLMs can invoke, the attack surface expands. You now have to worry about OAuth token handling, input validation for tool parameters, and scope limits on what tools can access.
I'll be covering MCP security in depth at CactusCon in my talk "Breaking Model Context Protocol: OAuth 2.0 Lessons We Didn't Learn."
Conclusion#
Coding with LLMs is fast, powerful, and risky. They'll generate working code that's insecure, incomplete, or context-blind. The fix isn't to stop using them. It's to build defensive layers that catch mistakes before they ship.
The stack that works:
- Pre-commit hooks block obvious problems (secrets, type errors, anti-patterns)
- Automated review agents catch logic errors and context mismatches
- Comprehensive CI enforces security scans, tests, and build verification
- CLAUDE.md context files teach LLMs your patterns and requirements
The cost is ~30 seconds per commit and ~$20/month in API calls. The benefit is a reliable safety net between LLM-generated code and production.
These aren't theoretical patterns. They're running in my repos right now, catching issues weekly. If you're using LLMs to write code, you need these layers.
Start with pre-commit hooks (easiest win). Add security review agents (highest ROI). Build up comprehensive CI from there.
All examples in this post are from my open-source repos: taskmanager, agents, and workflows. Feel free to copy patterns that work for your setup.
I'll be speaking about MCP security at CactusCon. If you're interested in how these patterns apply to tool-calling architectures, come find me there.